Visual Decoding and Reconstruction via EEG Embeddings with Guided Diffusion
🔥INFO
Blog: 2025/07/30 by IgniSavium
- Title: Visual Decoding and Reconstruction via EEG Embeddings with Guided Diffusion
- Authors: Dongyang Li et al. (Southern University of Science and Technology)
- Published: March 2024
- Comment: NIPS2024
- URL: https://arxiv.org/abs/2403.07721
🥜TLDR: diffusion prior + SDXL-Turbo + IP-Adapter
Motivation
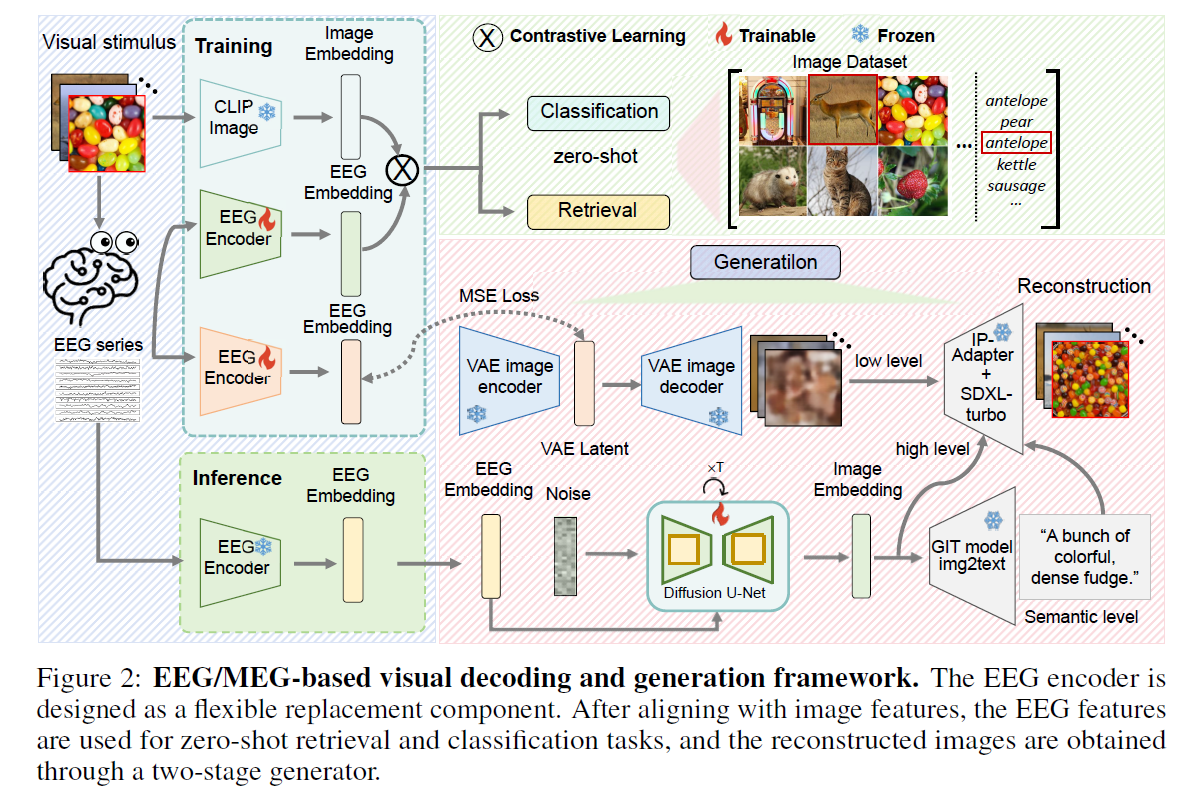
This paper aims to address the limited practicality and performance gap of EEG-based visual decoding compared to fMRI-based methods by introducing a novel zero-shot EEG-to-image reconstruction framework that achieves state-of-the-art results through a tailored encoder and two-stage generation (prior diffusion to convert \(Z_{EEG}\) to \(Z_{img}\)) strategy, overcoming previous challenges like low signal quality and limited model design.
Model
Architecture
EEG Encoder (Channel-wise Transformer + Synthesis Module):
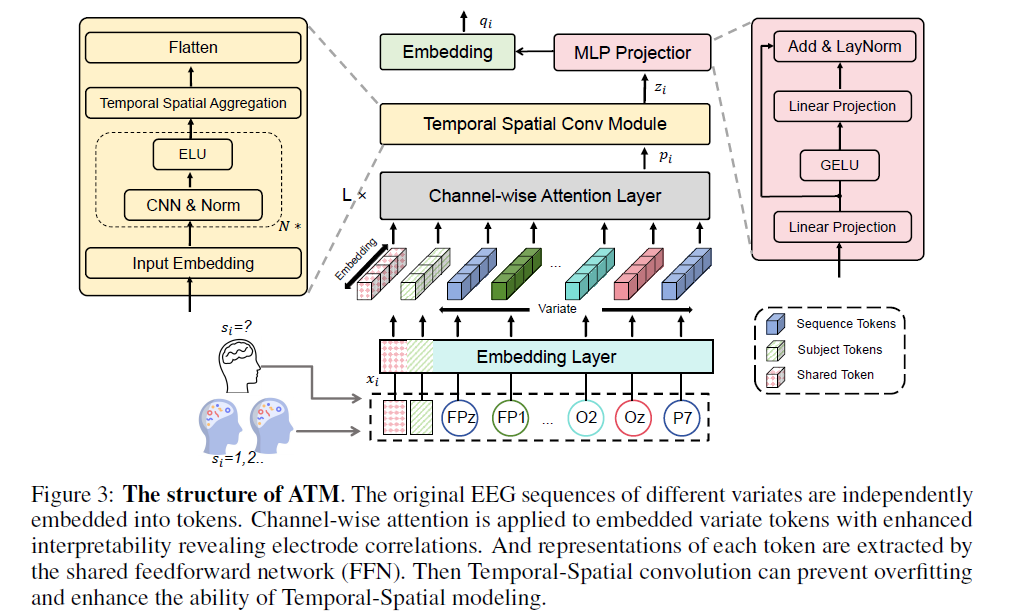
Image Reconstruction training uses weighted loss of these two:
- contrastive loss between EEG-Encoder and CLIP Visual Encoder (\(R^{1024}\) in ViT-14/Large)
- MSE to encoder EEG into image's VAE latent
Two-stage EEG-guided image generation pipeline using conditional diffusion models (ref. DALLE-2):
- Stage I – EEG-Conditioned Diffusion: EEG embeddings condition a diffusion model to generate CLIP image embeddings using a U-Net and classifier-free guidance.

-
Stage II – Image Synthesis: The generated CLIP embedding guides image generation using pre-trained SDXL(Stable Diffusion) and IP-Adapter (ImagePrompt: adapter weights for image-embedding-conditioned SD), with optional acceleration via SDXL-Turbo.
-
Low-Level Pipeline: To recover fine visual details (e.g., contours, posture), EEG featurevs are aligned with VAE latents. Only latent-space loss works reliably; full image-level losses are unstable and memory-intensive.
-
Semantic-Level Pipeline: EEG-derived image features generate captions via GIT, optionally guiding generation via text prompts. Due to potential semantic drift, this step is not always applied.
Evaluation
Overall Performance
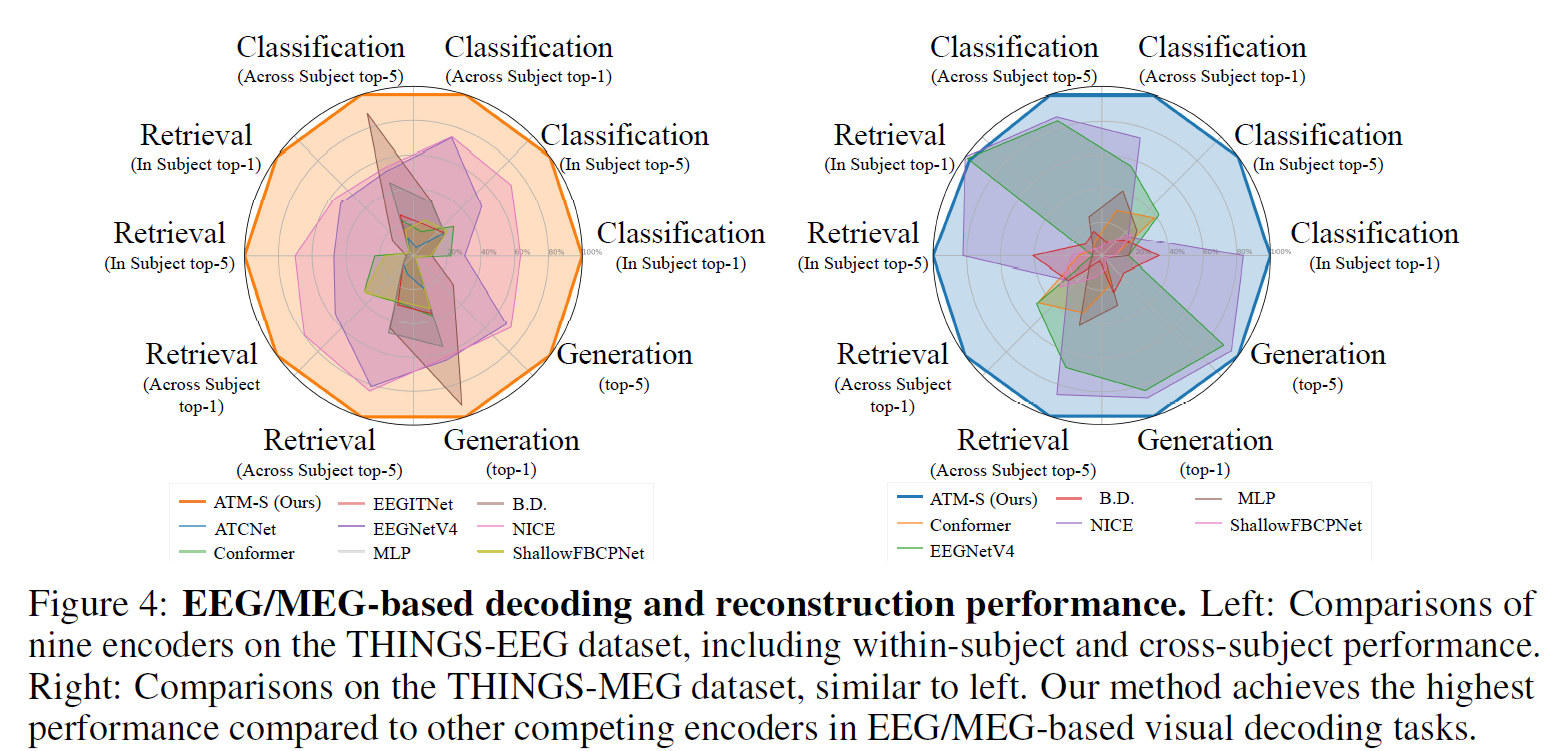
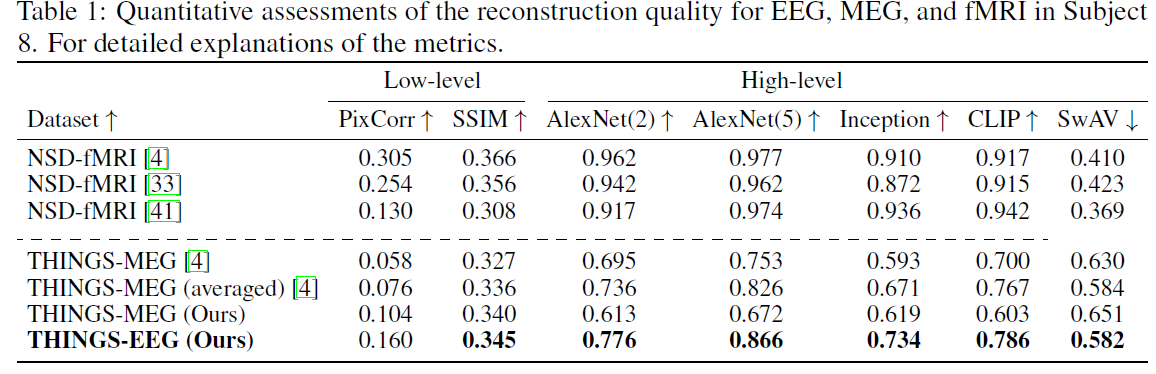
Reconstruction Performance
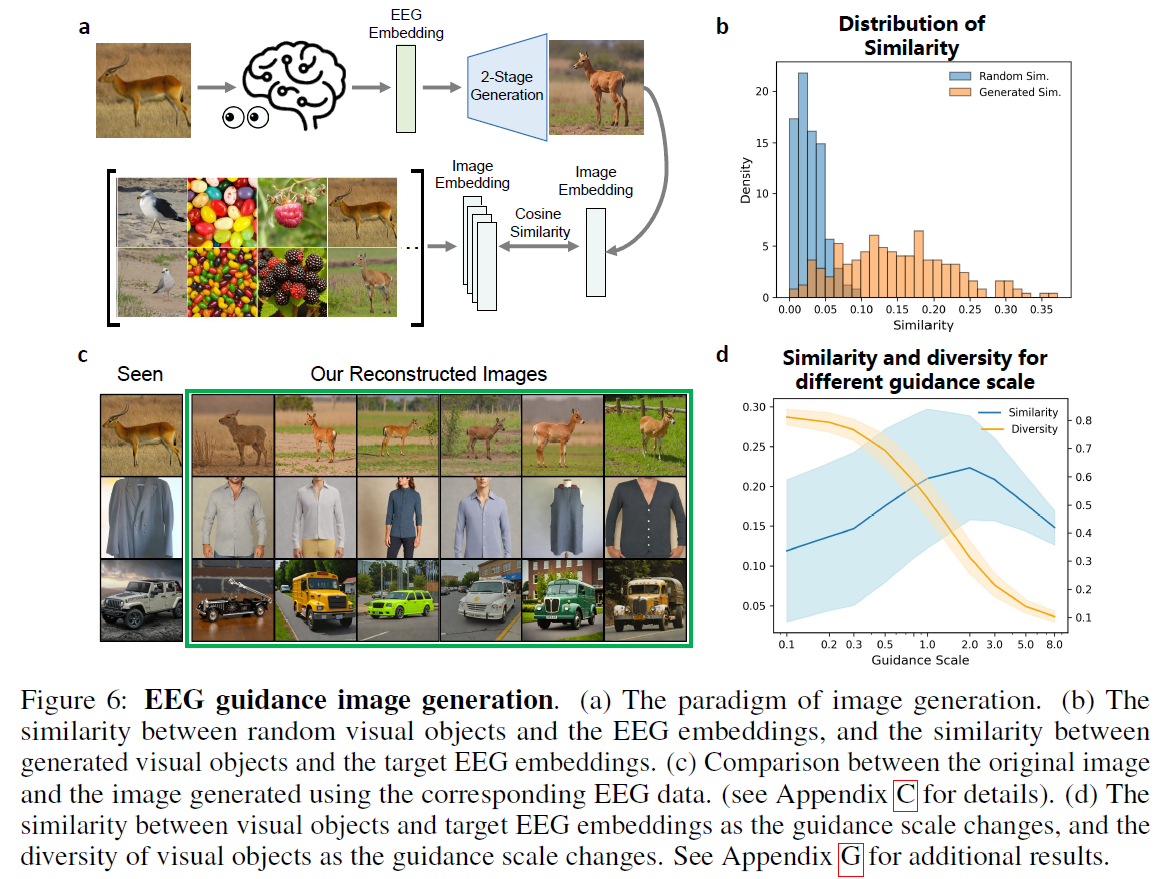
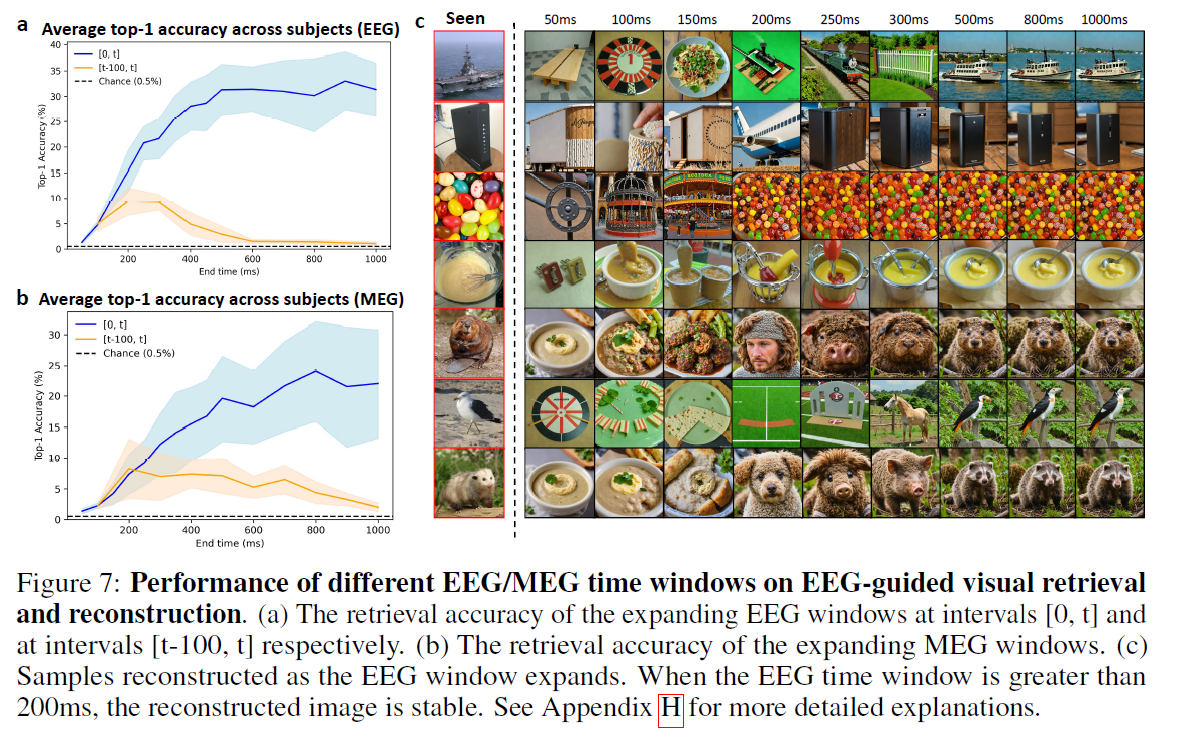
Temporal and Spatial Interpretability
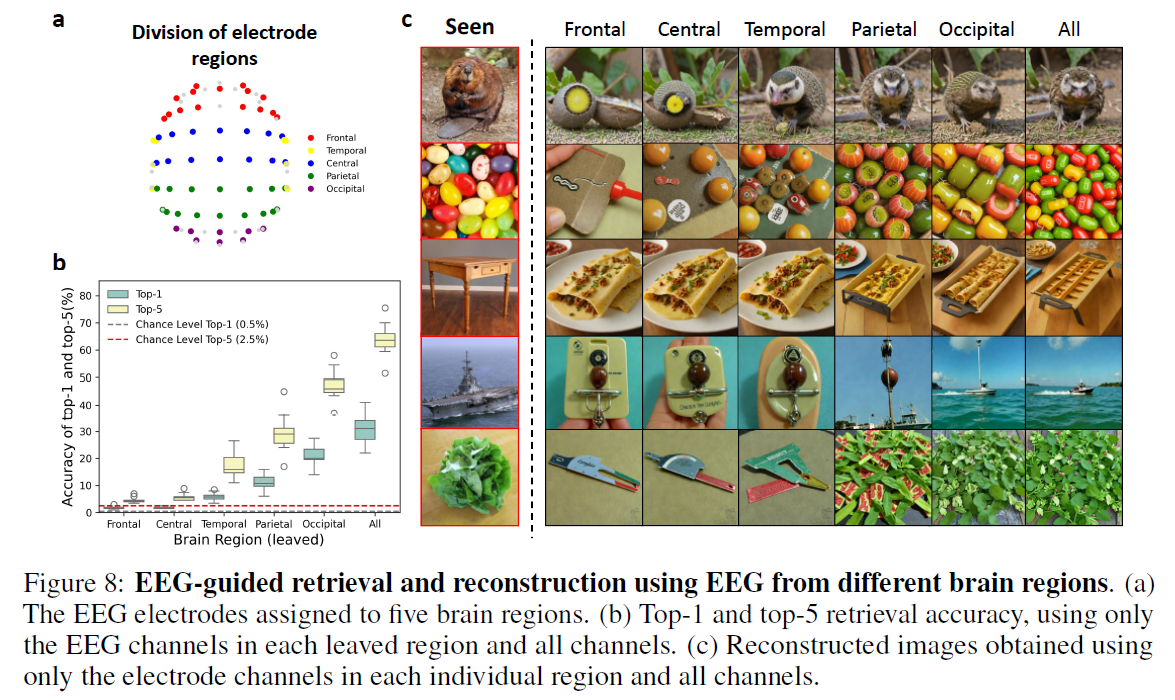
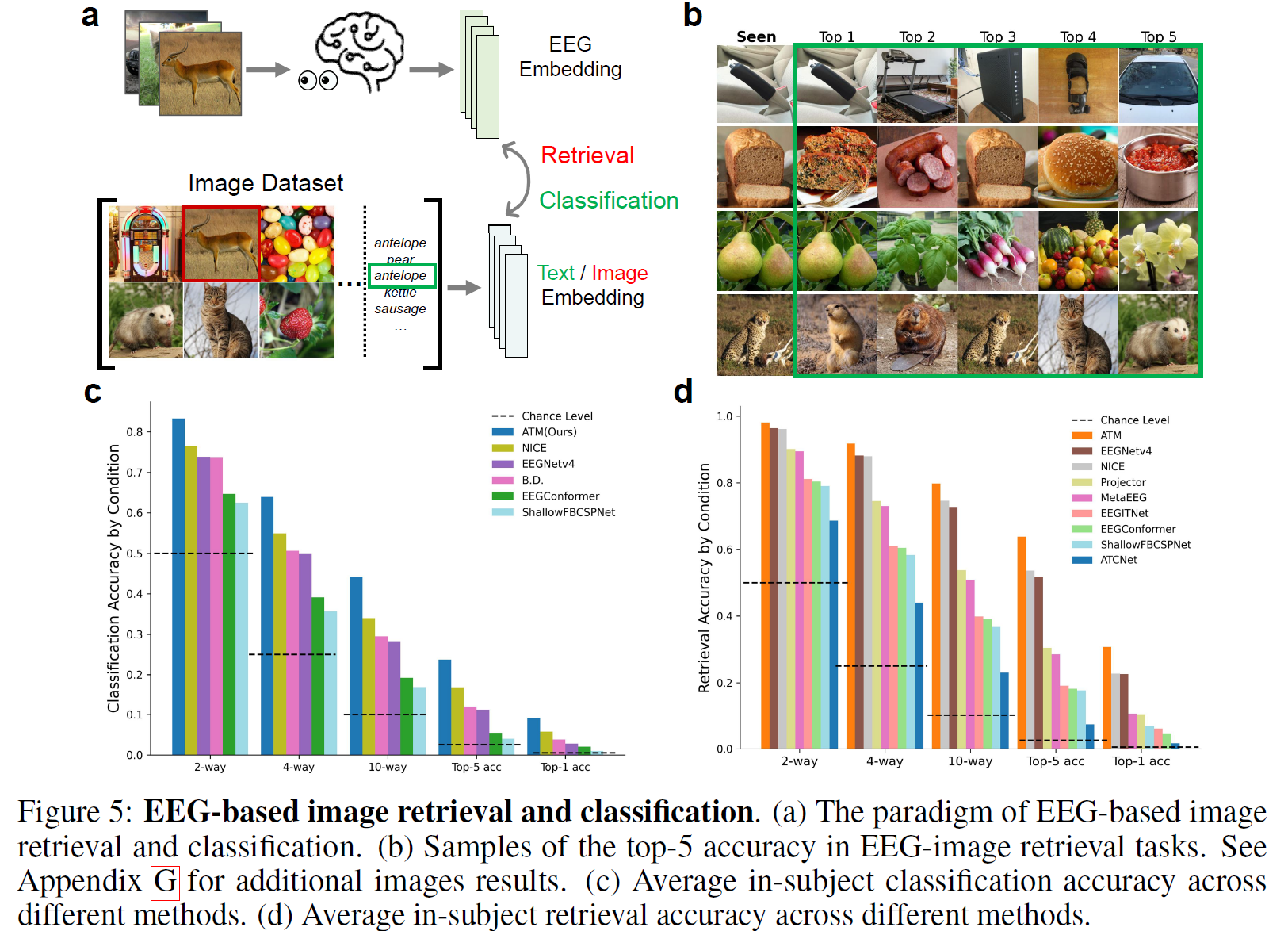
Retrieval and Classification Performance