UniBrain: Unify Image Reconstruction and Captioning All in One Diffusion Model from Human Brain Activity
🔥INFO
Blog: 2025/07/28 by IgniSavium
- Title: UniBrain: Unify Image Reconstruction and Captioning All in One Diffusion Model from Human Brain Activity
- Authors: Weijian Mai, Zhijun Zhang (South China University of Technology)
- Published: August 2023
- Comment: arxiv
- URL: https://arxiv.org/abs/2308.07428
🥜TLDR: Versatile Diffusion(VD) supporting both visual and textual input and output
Motivation
This paper proposes UniBrain, a unified multi-modal diffusion model to overcome the limitations of prior fMRI-based methods—such as separate pipelines and reliance on scarce training data—by enabling simultaneous high-fidelity image reconstruction and captioning without model training or fine-tuning.
Model
Architecture
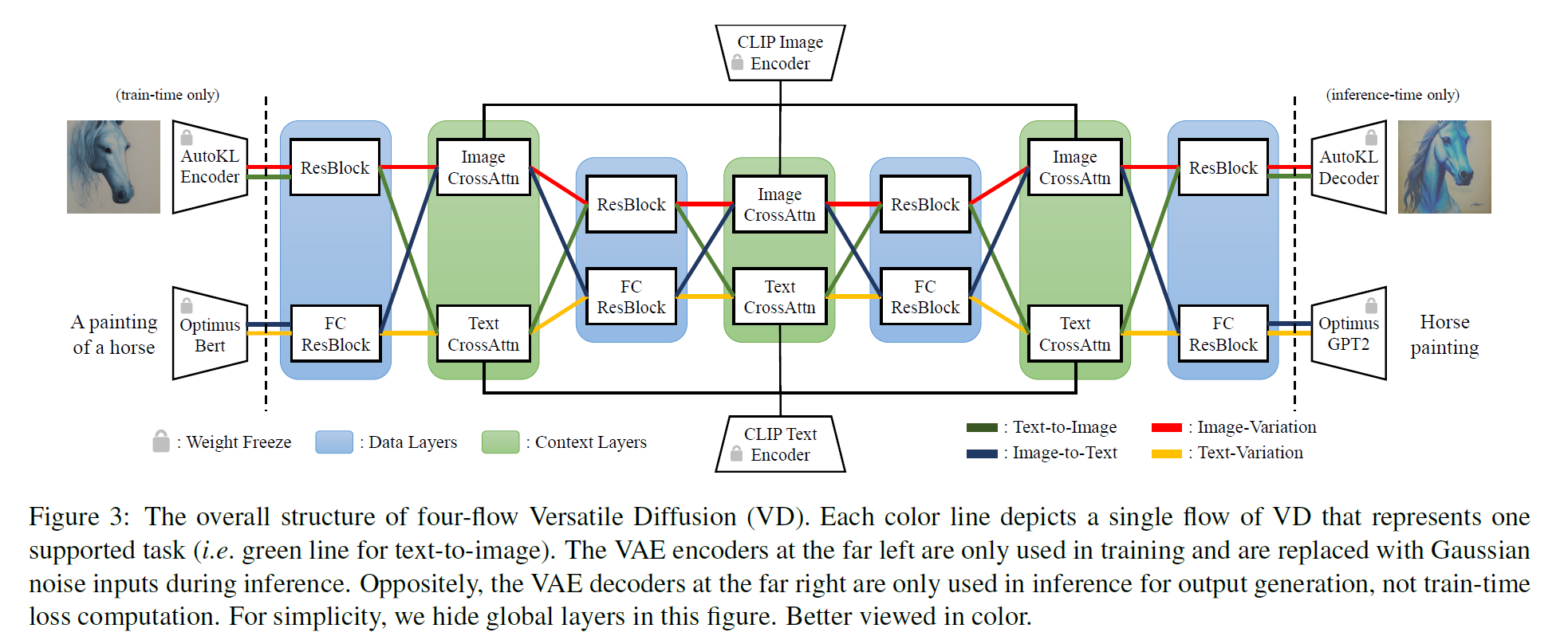
Original Versatile Diffusion(VD) architecture:
UniBrain based on Versatile Diffusion(VD) Framework:
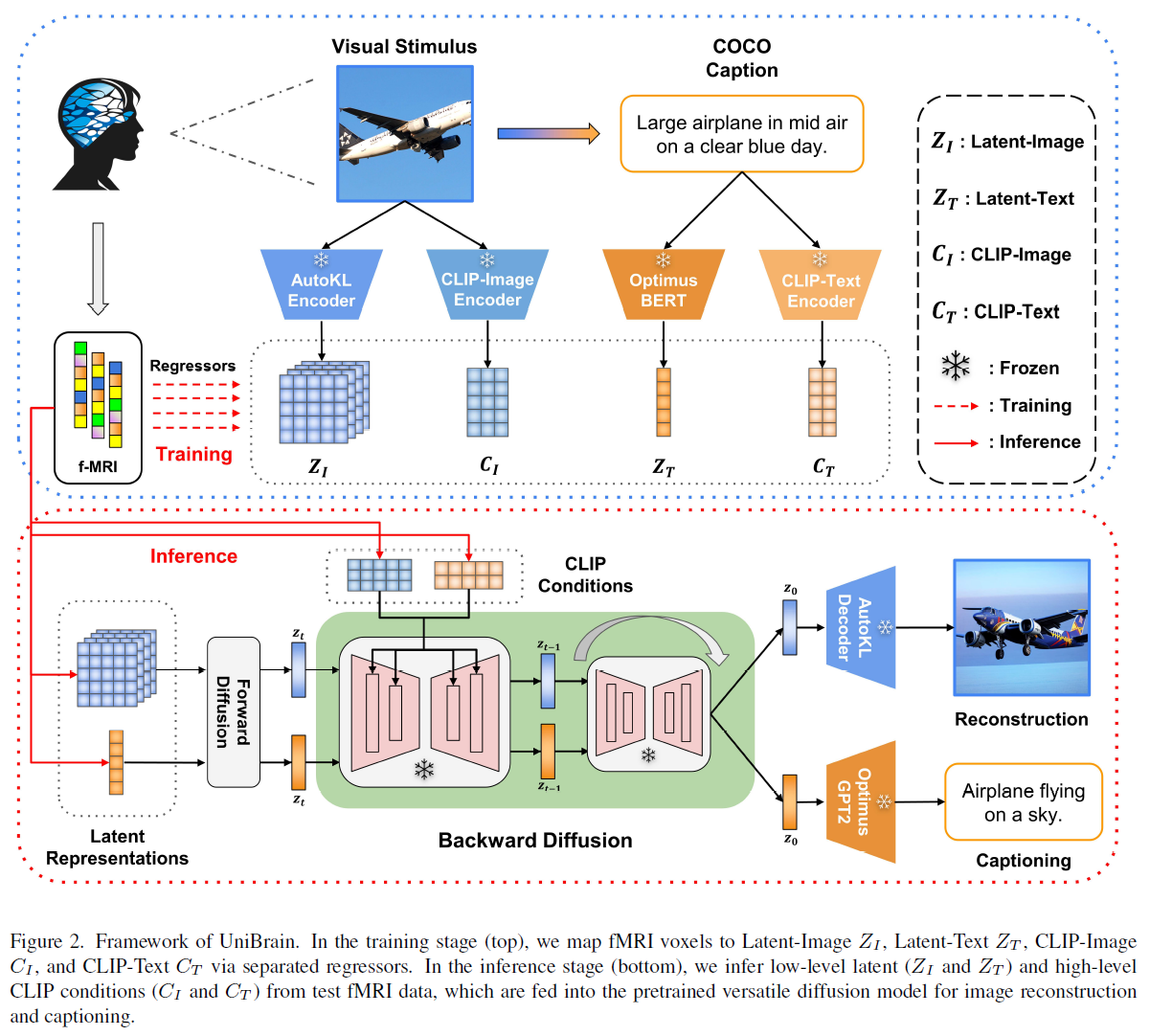
It encodes visual stimuli and COCO captions into low- (\(Z_I\), \(Z_T\)) and high-level (\(C_I\), \(C_T\)) representations via frozen pretrained encoders(Consistent with original Versatile Diffusion model)——Four small regressors map fMRI to these representations.
During testing:
- Image reconstruction: \(Z_I\) is inferred and denoised via diffusion guided by \(C_I\) and \(C_T\), then decoded into an image by AutoKL Encoder.
- Captioning: \(Z_T\) is inferred and denoised via diffusion guided by \(C_I\) and \(C_T\), then decoded into text via Optimus GPT2, with repeated sentences removed.
CLIP-Image and CLIP-Text jointly guide diffusion using a U-Net cross_attention matrix liner interpolation.
Implementation
UniBrain uses Ridge regression to map fMRI to latent features, addressing multicollinearity. It runs 50 diffusion steps with strength 0.75 for both image and text reconstruction. The CLIP condition mixing rates are set to 0.6 for image reconstruction and 0.9 for captioning to optimize performance.
Evaluation
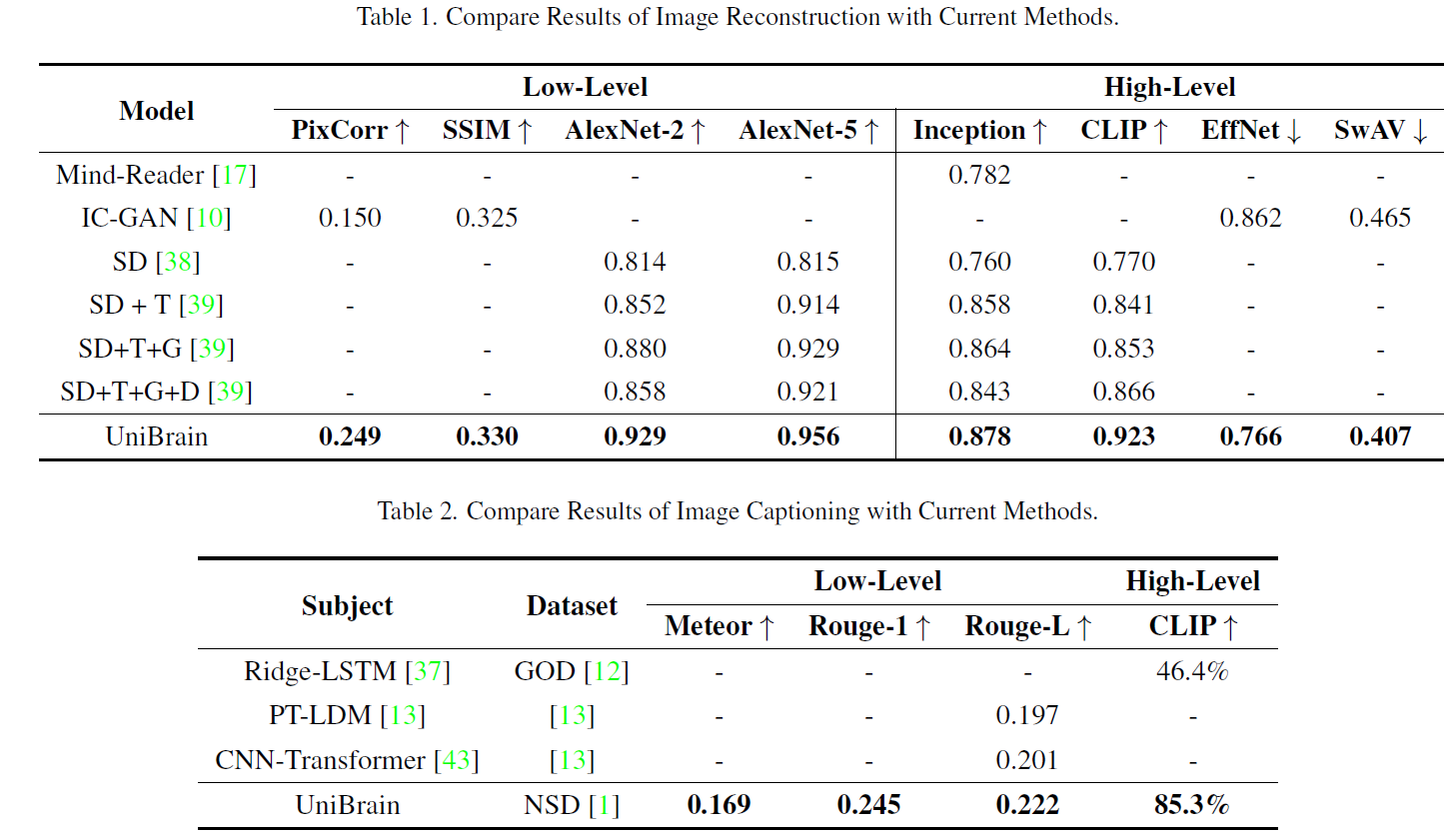
Quantitative Results

Performance

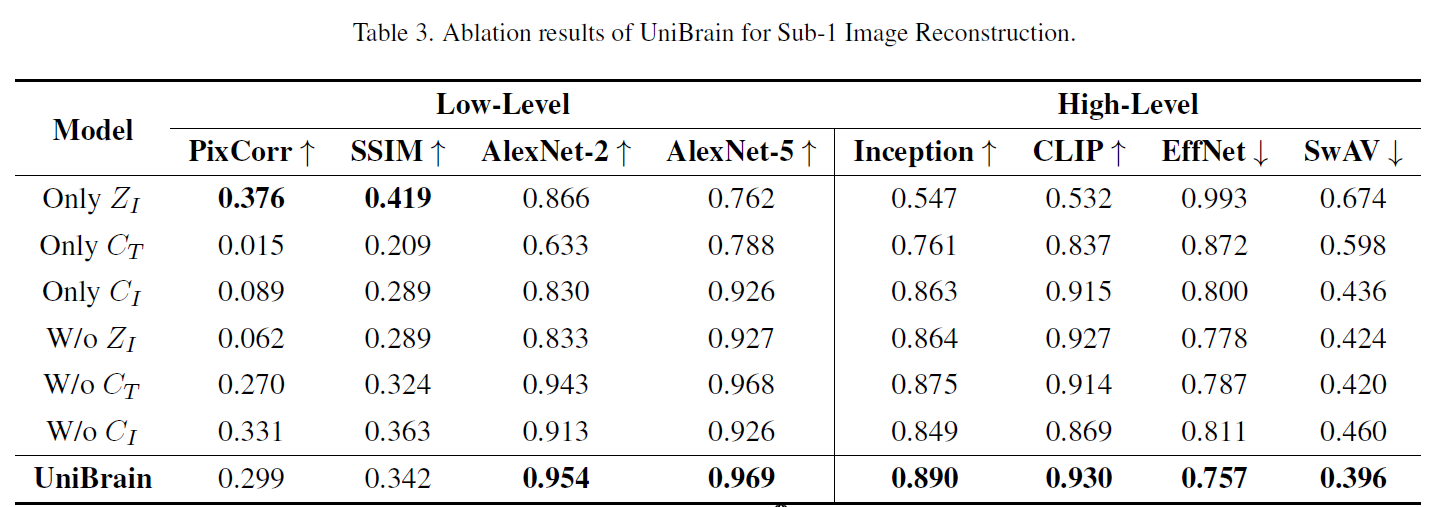
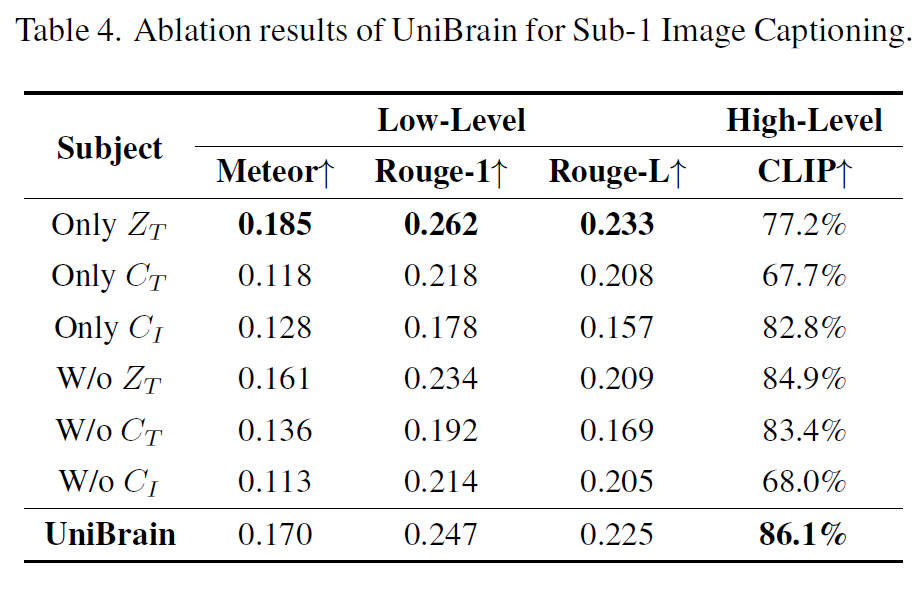
Ablation
\(Z_I\) or \(Z_T\) (latent encoder) mainly captures low-level semantics (overall image or caption structure e.g. position orientation size) and \(C_I\) or \(C_T\) (CLIP encoder) mainly captures high-level semantics (e.g. category attribute)
Note that, even when combined with \(C_T\) and \(Z_I\) , as with Takagi et al. [38], all quantitative high-level performance of the ‘W/o \(C_I\) ’ model is still worse than the ‘Only \(C_I\) ’ model. This phenomenon explains why UniBrain is superior to SD [38], since SD ignores the \(C_I\) features.

Synthetic RoI-specific fMRI analysis

🧐Reflections
We should consider the Model Size comparison between SD and VD.
This VD-based UniBrain framework emphasized the importance of \(C_I\) i.e. image clip features as backward diffusion conditions.