Reconstructing Visual Stimulus Images from EEG Signals Based on Deep Visual Representation Model
🔥INFO
Blog: 2025/07/29 by IgniSavium
- Title: Reconstructing Visual Stimulus Images from EEG Signals Based on Deep Visual Representation Model
- Authors: Weijian Mai, Zhijun Zhang (South China University of Technology)
- Published: March 2024
- Comment: IEEE Transactions on Human-Machine Systems
- URL: https://ieeexplore.ieee.org/document/10683806
🥜TLDR: VAE framework to reconstruct digit imgs
Motivation
This paper aims to address the limitations of costly and less portable fMRI-based visual image (only consider numbers & letters) reconstruction by proposing a novel EEG-based method that fundamentally learns deep visual representations—unlike prior EEG approaches that relied heavily on generative models without effectively bridging EEG signals and visual semantics.
Model
Data
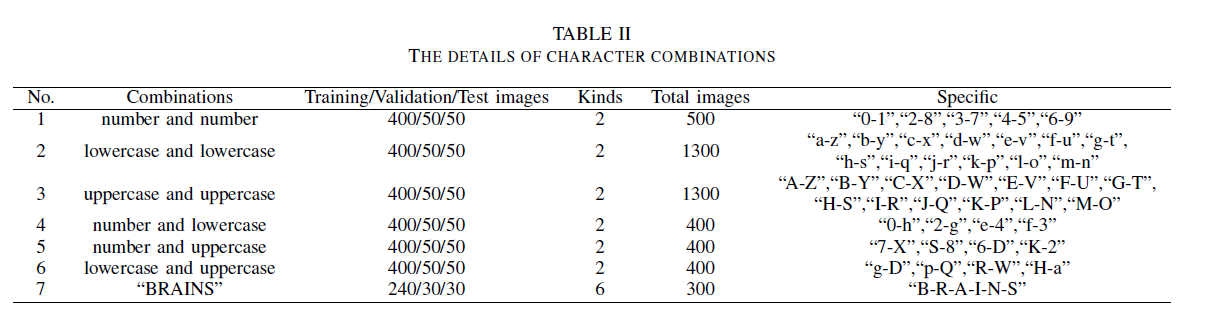
The EEG dataset was collected from four healthy subjects (two males and two females, aged 22–26) using a 32-channel EMOTIV EPOC Flex device at a 128 Hz sampling rate, during visual presentation of character images (numbers, uppercase, and lowercase letters) in three parts; each character type was shown for 100 s with 1 s image display and 1 s idle intervals, producing 50 trials (i.e. fonts) per type, with preprocessing including 1–64 Hz bandpass filtering, baseline correction using the 1000 ms prior to stimulus onset, and discarding the first 100 time steps of each trial to reduce interference.
Architecture
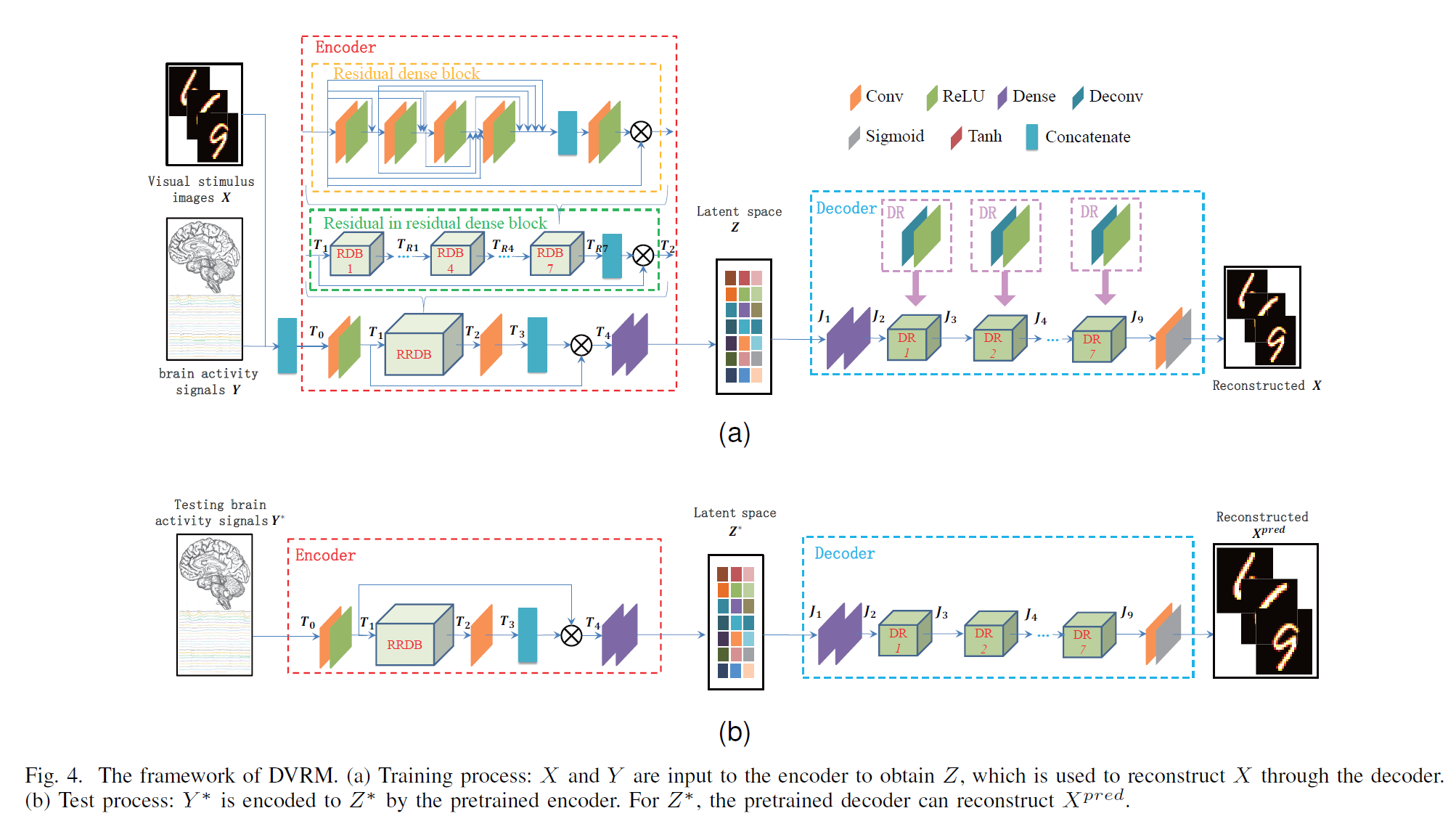
VAE-like framework:


🧐It is intuitively equivalent with train a EEG Encoder to map EEG to Image VAE latent.
Evaluation
We divided the EEG dataset (26 characters: A to Z; 26 characters: a to z; 10 characters: 0 to 9) three parts: training set, validation set, and test set, which are divided as 80%, 10%, and 10%, respectively.
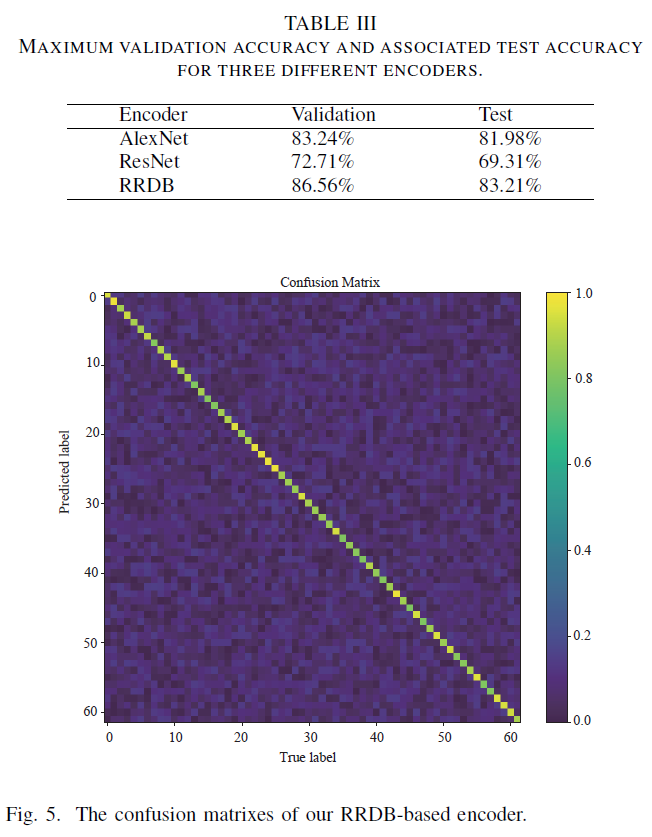
Encoder Performance
K Nearest Neighbor Classifier:
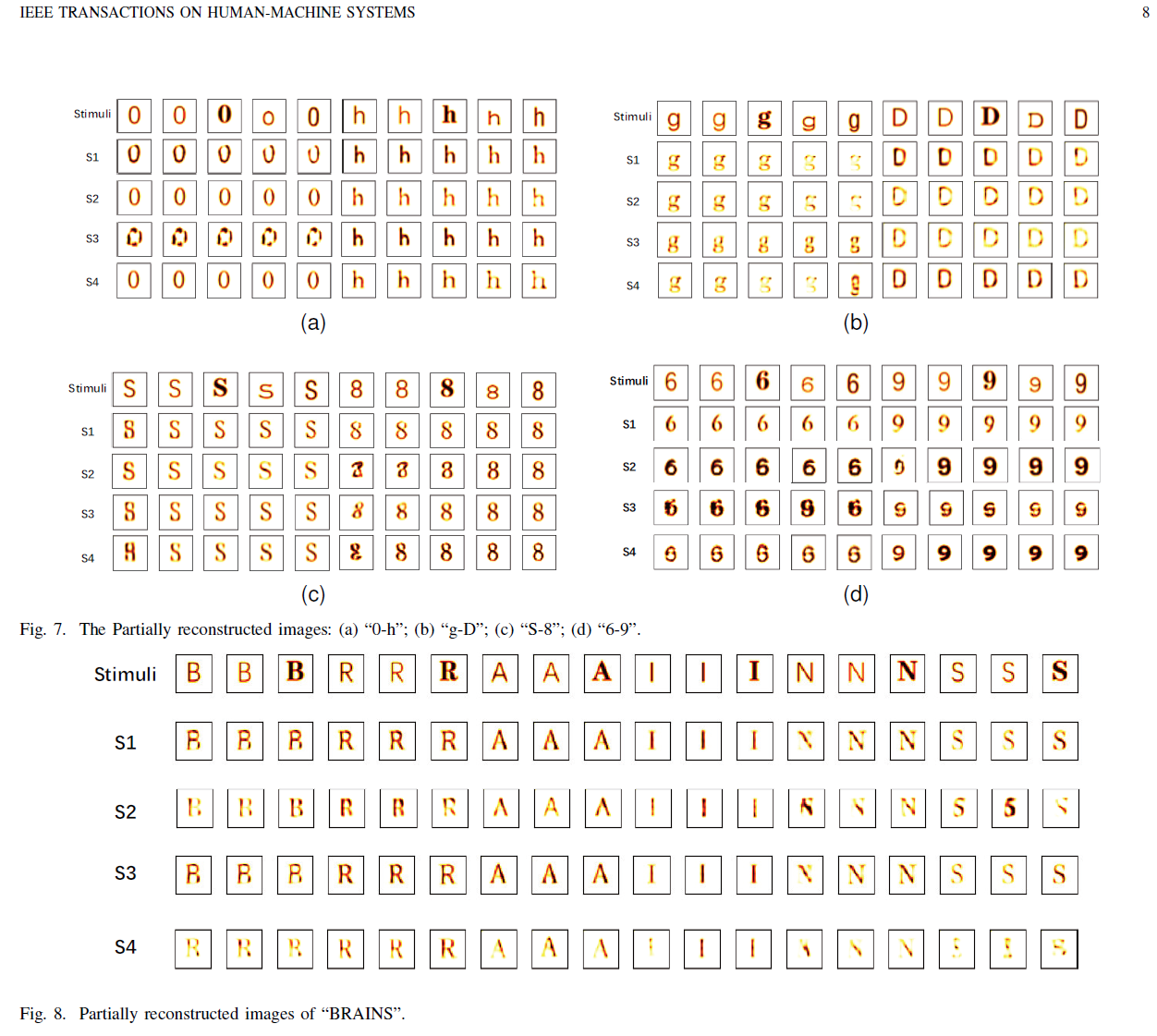
Data Distribution Influence on Image Reconstruction
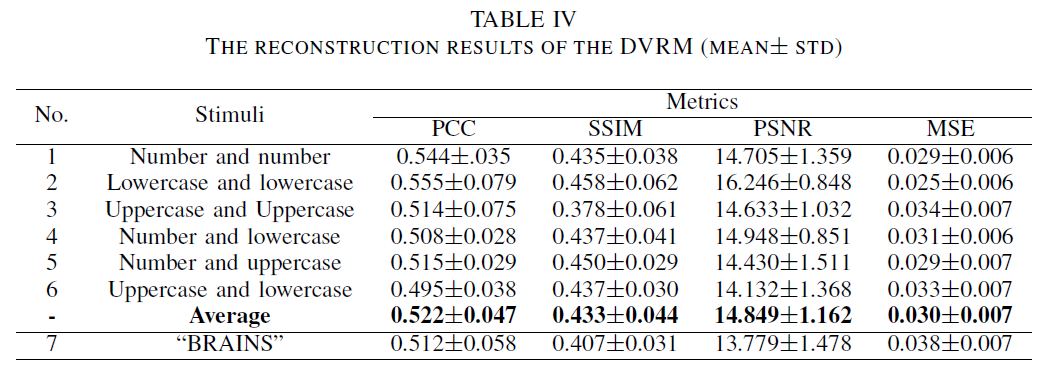
The study demonstrates that the distribution of character type combinations in the training data significantly impacts the performance of EEG-based image reconstruction. Specifically, combinations involving the same character type (e.g., lowercase–lowercase) yield better reconstruction results than mixed-type combinations. This is likely because characters of the same type share more consistent visual patterns, making it easier for the model to learn EEG-to-image mappings. Furthermore, the model also performs well on semantically meaningful character sets (e.g., “BRAINS”), indicating its ability to reconstruct recognizable images even with limited and specific input categories.
Qualitative Results
🧐Seemingly NOT style-sensitive enough (comparing different "g" styles)
🧐Maybe the training data is NOT style balanced (i.e. many kinds of font actually have overall similar styles)