DreamDiffusion: Generating High-Quality Images from Brain EEG Signals
🔥INFO
Blog: 2025/07/22 by IgniSavium
- Title: DreamDiffusion: Generating High-Quality Images from Brain EEG Signals
- Authors: Yunpeng Bai, Chun Yuan (THU Shenzhen Inernational)
- Published: June 2023
- Comment: ECCV
- URL: https://www.ecva.net/papers/eccv_2024/papers_ECCV/papers/04605.pdf
🥜TLDR: Highlight is a MAE (very large scale) self-supervised learning method for EEG Encoder.
Motivation
This research aims to enable direct, high-quality image generation from EEG signals—overcoming the limitations of prior work that relied on costly, non-portable fMRI or poorly aligned EEG-text-image mappings—by leveraging pre-trained diffusion models and novel temporal EEG pretraining (masked signal modeling) to realize low-cost, accessible “thoughts-to-image” applications.

Model
Architecture
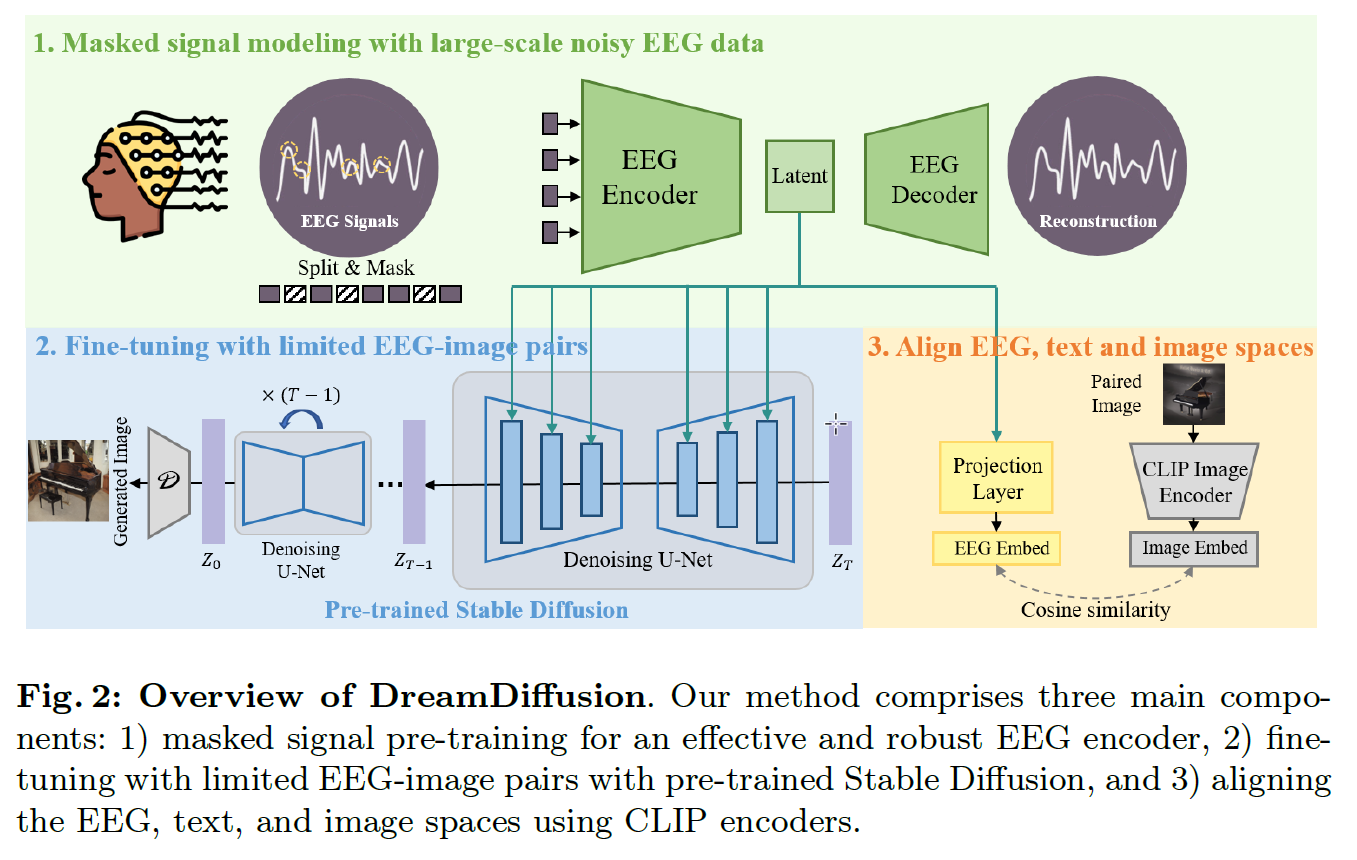
self-supervised learning for EEG modeling
Given the high temporal resolution of EEG signals, we first divide them into tokens in the time domain, and randomly mask a certain percentage of tokens. Subsequently, these tokens will be transformed into embeddings by using a one dimensional convolutional layer. Then, we use an asymmetric architecture such as MAE to predict the missing tokens based on contextual cues from the surrounding tokens.
reconstruction loss is only applied at masked token and unified across all EEG channels.
fine-tuning with Stable Diffusion Framework
only update the encoder(+projector) and the cross_attn in U-Net (denoise network in SD) with combined loss:
- original image reconstruction loss
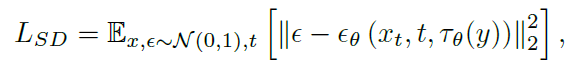
- align projected feature to CLIP description feature
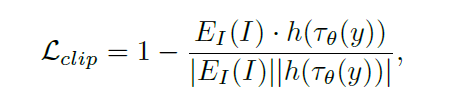
The pre-trained Stable Diffusion model is specifically trained for text-to-image generation; however, the EEG signal has its own characteristics, and its latent space is quite different from that of text and image. Therefore, directly fine-tuning the Stable Diffusion model using limited EEG-image paired data is unlikely to accurately align the EEG features with the text embeddings (🧐CLIP embeddings in SD).
Data
Due to variations in the equipment used for data acquisition, the channel counts of these EEG data samples differ significantly. To facilitate pre-training, we have uniformly padded all the data that has fewer channels to 128 channels by filling missing channels with replicated values.
Evaluation
Performance
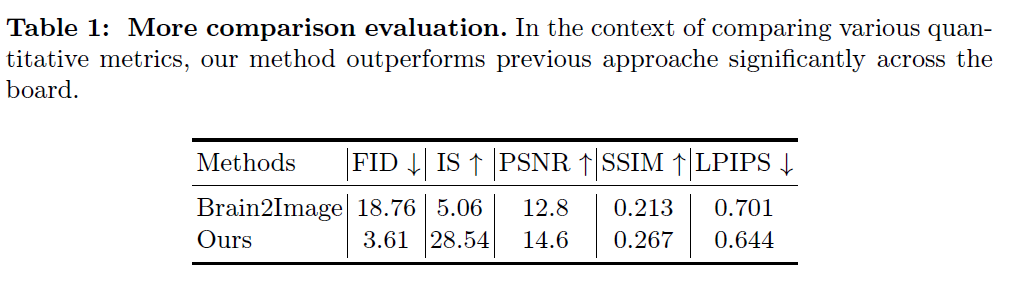
1. FID (Fréchet Inception Distance)
Purpose: Measures the difference in feature space distribution between generated and real images.
Formula:
$$
\mathrm{FID} = |\mu_r - \mu_g|_2^2 + \mathrm{Tr}\left( \Sigma_r + \Sigma_g - 2(\Sigma_r \Sigma_g)^{1/2} \right)
$$
- \(\mu_r, \Sigma_r\): Mean and covariance of real image features.
- \(\mu_g, \Sigma_g\): Mean and covariance of generated image features.
- Features are typically extracted from a layer of the Inception-V3 network.
2. PSNR (Peak Signal-to-Noise Ratio)
Purpose: Evaluates pixel-level error in image reconstruction/compression.
Formula:
- \(MAX_I\): Maximum pixel value of the image (usually 255).
- \(\mathrm{MSE}\): Mean Squared Error, calculated as:
3. LPIPS (Learned Perceptual Image Patch Similarity)
Purpose: Evaluates perceptual differences between images (aligned with human vision).
Formula (based on deep features):
- \(y^l, \hat{y}^l\): Feature maps extracted from layer \(l\) (normalized).
- \(w_l\): Learned weights for each layer.
- Measures differences in deep feature representations, not pixel-level.


Ablation
🧐Only tuning the pretrained encoder with CLIP text supervision yields obvious worse acc. compared with both tuning the encoder and the cross_attn in U-Net. Maybe it's because this framework doesn't map the EEG feature to the original image's latent state (z).
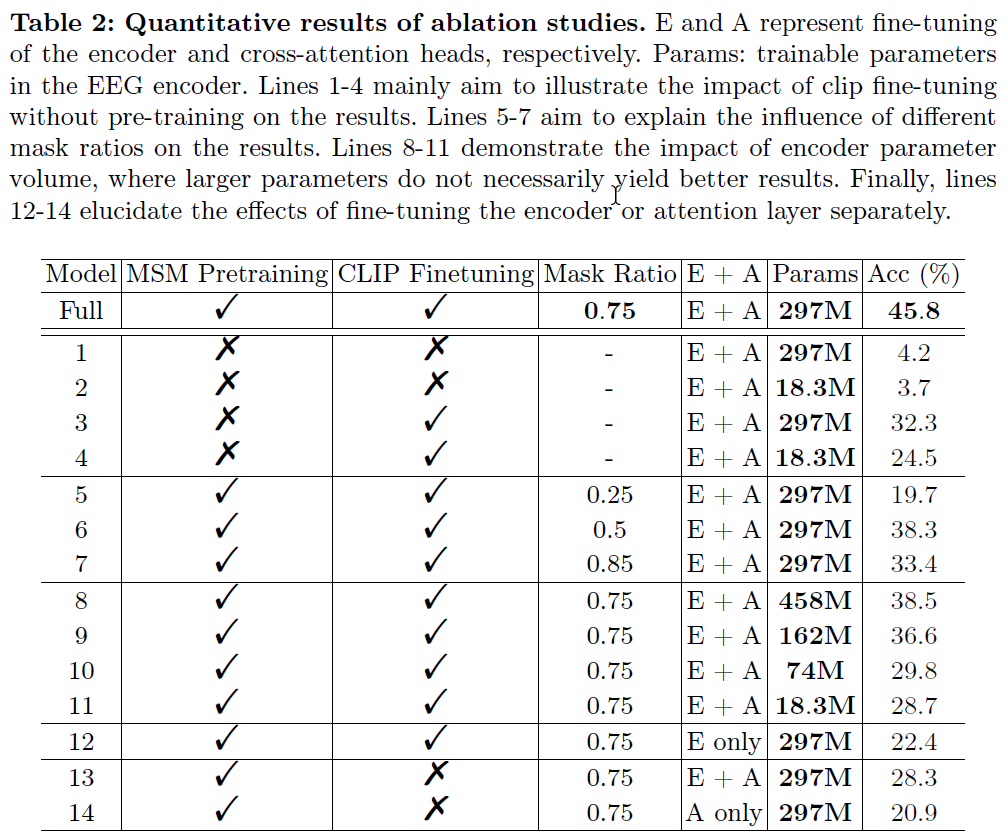

🧐Reflection
We can try implement CLIP alignment first, and then implement image reconstruction tuning later. i.e. divide this combined loss into two consequent process.