BrainVis: Exploring the Bridge between Brain and Visual Signals via Image Reconstruction
🔥INFO
Blog: 2025/07/23 by IgniSavium
- Title: BrainVis: Exploring the Bridge between Brain and Visual Signals via Image Reconstruction
- Authors: Honghao Fu, Hao Wang et.al (HKUST-Guangzhou)
- Published: December 2023
- Comment: BrainVis: Exploring the Bridge between Brain and Visual Signals via Image Reconstruction
- URL: https://arxiv.org/abs/2312.14871
🥜TLDR: This paper introduces BrainVis, which reconstructs semantically accurate images from EEG by enhancing representations with (large scale) self-supervised learning and CLIP-based alignment.
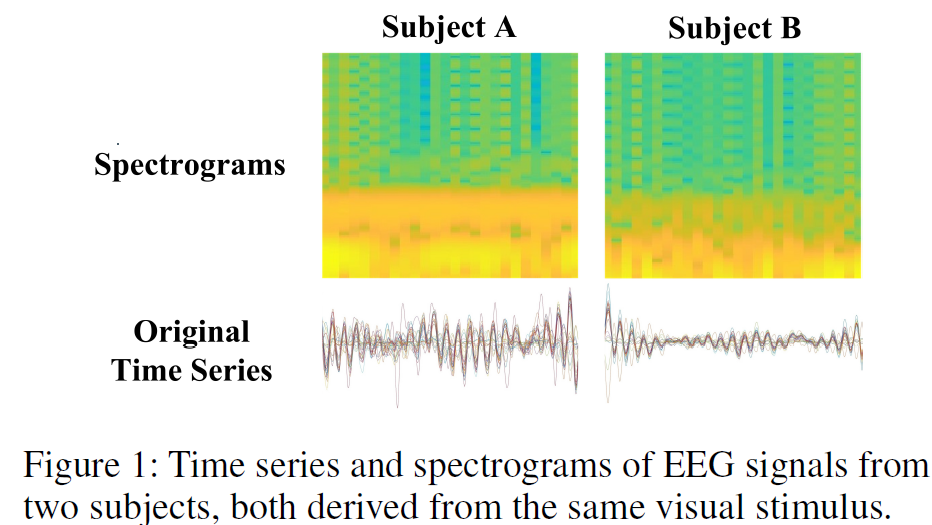
Motivation
This paper is motivated by the challenge of reconstructing semantically accurate images from noisy EEG signals—addressing limitations of previous methods (i.e. Dream Diffusion) such as weak EEG feature embedding, reliance on large (self-supervision) datasets, and inability to capture fine-grained semantics—by proposing BrainVis, which enhances EEG representation through self-supervised learning (latent masked modeling) and frequency features, and improves cross-modal alignment with CLIP-based semantic interpolation, achieving superior results with significantly less training data.
Model
Architecture
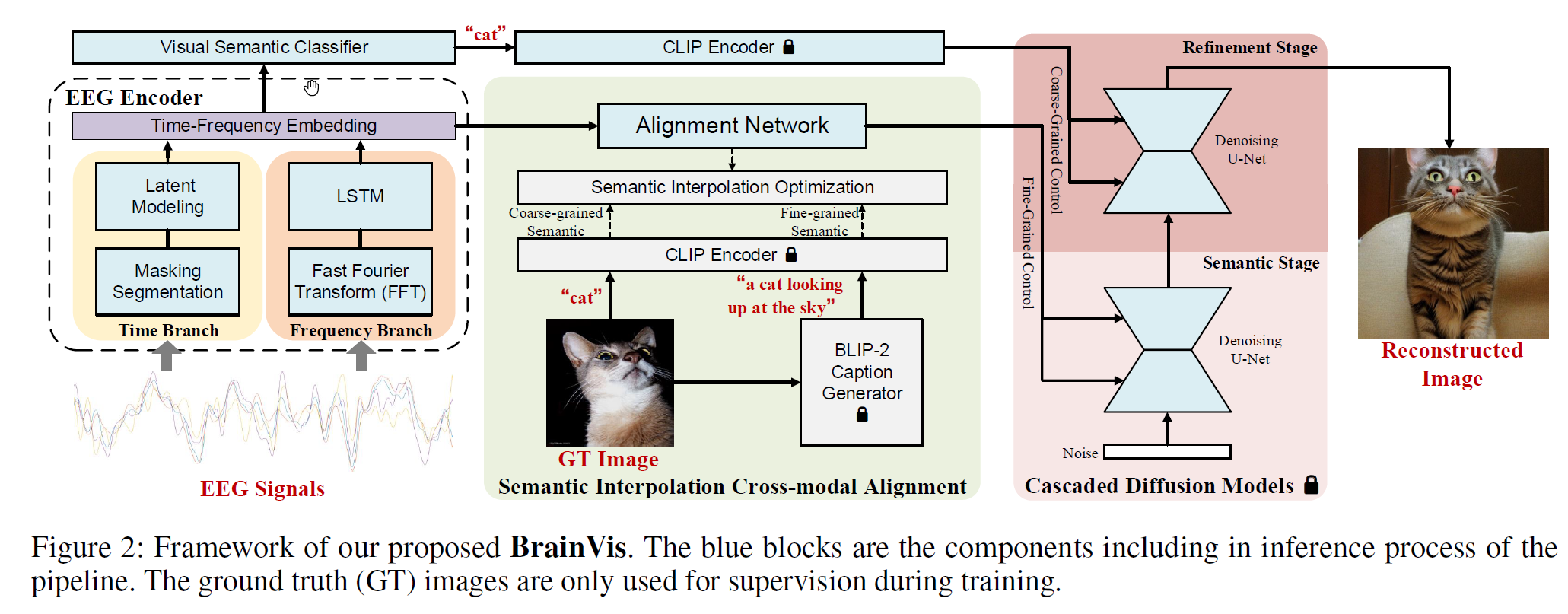
The main target is to map EEG to conditional text input embeddings in Stable Diffusion.
Pretraining
Time Branch
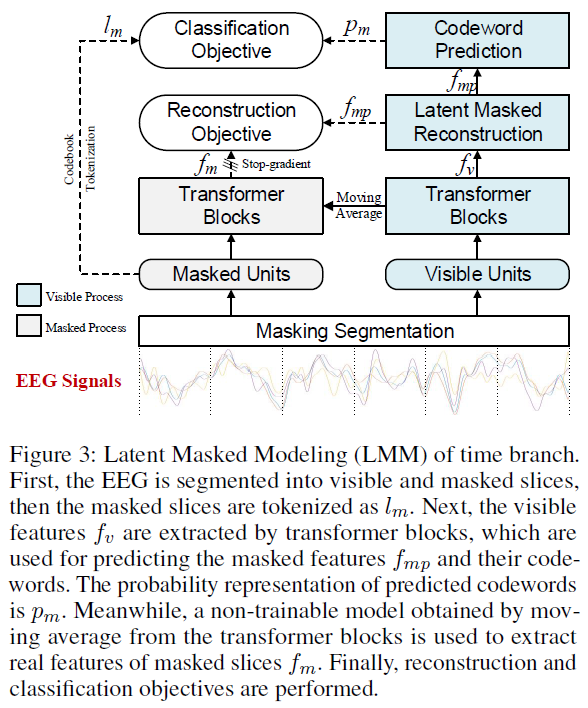
The Latent Masked Modeling (LMM) pre-training method enhances EEG time-domain feature learning by dividing the signal \(x \in \mathbb{R}^{c \times l}\) into n units, projecting each into d-dimensional embeddings \(z \in \mathbb{R}^{n \times d}\), and applying random masking (ratio \(r_m\)) for self-supervised learning; the model optimizes two objectives: (1) regression loss \(L_{\text{reg}} = \frac{1}{d} \| f_m - f_{mp} \|^2_2\) to reconstruct masked embeddings using transformer-based predictions, and (2) classification loss \(L_{\text{cls}} = -\mathbf{l}_m \cdot \log(\mathbf{p}_m)\) via codebook tokenization of masked units, with the total loss defined as \(L_{\text{lmm}} = L_{\text{reg}} + L_{\text{cls}}\).
(channel = 128, time_step = 440, n = 110, d = 1024, \(r_M\) = 0.75 and \(n_{\text{code}}\) = 660)
✨related work: Momentum Encoder ; Vector Quantized VAE
Frequency Branch
- Frequency Transformation: EEG signals are converted to the frequency domain using Fast Fourier Transform (FFT).
- Feature Extraction: An LSTM model is used to extract frequency features, avoiding overfitting risks of complex networks.
- Supervised Training: The LSTM is trained with visual classification labels using cross-entropy (CE) loss.
Unified Classify: The time and frequency branches are fine-tuned together using CE loss to form a unified time-frequency embedding.
CLIP alignment finetuing
Find a balance (simple sum of loss) between label-induced coarse text feature and description-induced fine text feature. (🧐Possibly tuned together with Unified Classify)

Refined SD Generation
Img2Img Refinement using EEG classification labels (inferred from Unified Classify) (using only ''label word" as refinement conditional text) to enhance image quality.
Evaluation
Performance
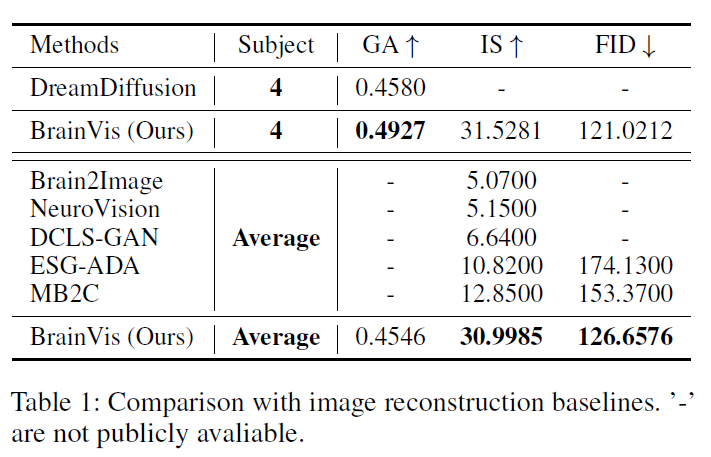
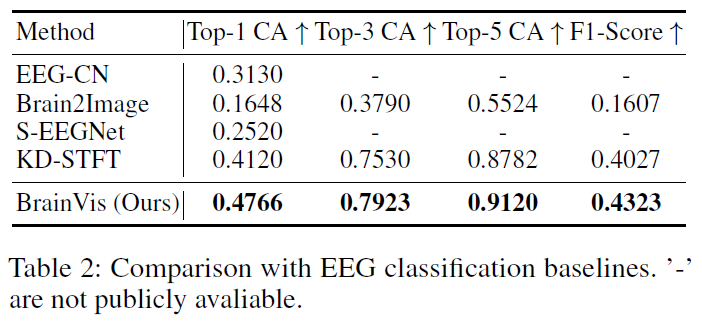


Ablation
🧐Time Branch is the main information source vs. Frequency Branch.
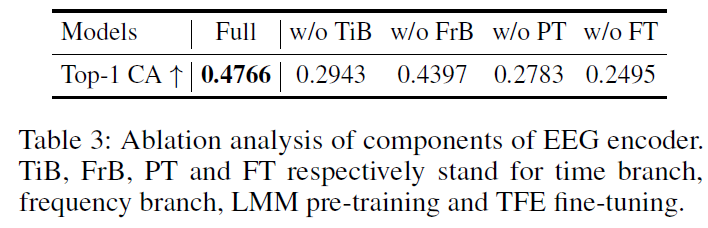
🧐Seems that refinement (single-label guided image2image SD refinement) dominates the output semantics, thus original image structure (size, position, orientation, action etc.) will be largely ignored.
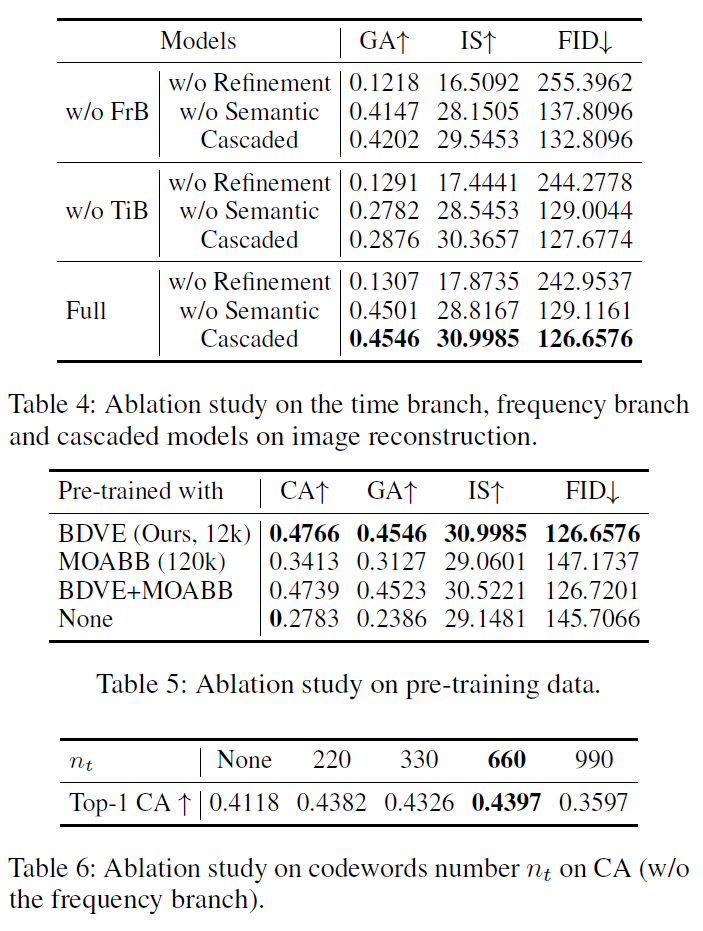
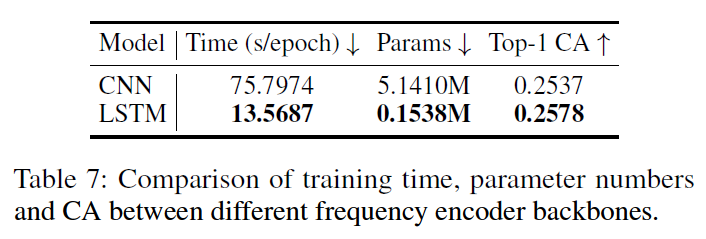
🧐Reflections
-
There's no experiment to show the effectiveness of MASKED LATENT MODELING classification objective (codebook design).
-
Seems that even simple object class recognition is still a little bit hard for EEG-signal analysis(acc. ~45%) compared with fMRI modeling(acc. ~75%) .
